

最近,一些使用 Google 翻譯的網友發現,這款產品突然“水逆”了。
在 Reddit 上,有網友截圖顯示,Google 翻譯將某些語種的詞彙翻譯成英語時,輸出的卻是毫無由頭的宗教語言。 比如鍵入19 個dog,將其從毛利語翻譯成英語時,輸出的卻是“距離十二點的世界末日還差三分鐘,我們正在經歷世界上的人物和戲劇性發展,這預示著我們正在無限 接近末日,耶穌回歸時日將近”。
但這只是眾多無厘頭翻譯的其中一例。 還有網友放出了很多“不詳”的翻譯內容。 例如,在索馬里語中,“ag”這個詞被翻譯成了“Gershon 的兒子”“耶和華的名字”,並且會引用聖經裡的“cubits”和Deuteronomy。
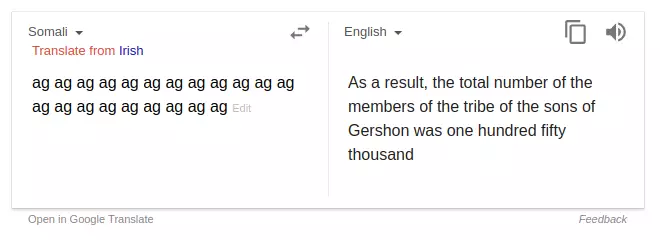
有網友留言稱其為“惡魔”或者“幽靈”,猜測這是 Google 員工的惡作劇,也有人建議設置“建議編輯”功能,讓用戶可以手動修改為正確內容。 Google 發言人 Justin Burr 在一封電子郵件中稱:“這只是一個將無意義的話語輸入系統,然後產生無意義輸出的功能。”
不過 Justin Burr 並未透露 Google 翻譯使用的訓練數據是否有宗教文本。 但上述詭異輸出內容很可能已被 Google 翻譯修正,AI科技大本營編輯輸入上述相同內容後並未發現異常。
但人們熱衷於探討 Google 翻譯出現如此結果的原因,業界不少專業人士也為此發聲。 哈佛大學助理教授 Andrew Rush 認為,這很可能與 2 年前 Google 翻譯技術的改變有關,它目前使用的是“神經機器翻譯”技術。
BBN Technologies 的科學家 Sean Colbath 從事機器翻譯工作,他認為奇怪的輸出可能是由於 Google 翻譯的算法試圖在混亂中尋找秩序。 他還指出,索馬里語、夏威夷語以及毛利語等產生最奇怪結果的語言,它們用於訓練的翻譯文本比英語或漢語等更廣泛使用的語言要少很多。 Google 也可能會使用像聖經等被翻譯成多種語言的宗教文本來訓練小語種模型,這也解釋了為什麼會最終輸出宗教內容。
前Google 員工Delip Rao 在其博客上則指出,當談到平行語料庫時,宗教文本是最低層次的共同標準資源,像“聖經”和“古蘭經”這樣的主要宗教文本,有各種各樣的語言 版本。
比如,如果你為政府部署一個 Urdu-to-English 的機器翻譯系統,那麼很容易將一堆已經翻譯成烏爾都語的宗教文本組合在一起。 因此,可以合理地假設 Google 的平行語料庫中包含所有的宗教文本,而對於許多資源不足的語言,它們不只是訓練語料庫中微不足道的部分。
那麼,為什麼我們看到 Google 翻譯會輸出宗教文本? 一種解釋是,因為宗教文本包含許多只會在宗教中出現的罕見詞,而這些詞在其他任何地方都不會出現。 因此,罕見的詞語可能會觸發解碼器中的宗教情境,尤其是當這些文本的比例很大時。 另一種解釋是該模型對輸入的內容沒有太多的統計支持,而輸出也只是解碼器模型的無意義採樣。
更重要的是,他想要指出現在的神經機器翻譯 真正存在的問題。
他特意總結了2017年Philipp Koehn和Rebecca Knowles撰寫的一篇論文,內容如下:
1. NMT 系統在域外數據上表現很差。 像 Google 翻譯這樣的通用 MT 系統,在法律或金融等專業領域的表現尤其糟糕。 此外,與基於短語的翻譯系統等傳統方法相比,NMT 系統的效果更差。 到底有多糟糕? 如下圖所示,其中非對角線元素表示域外結果,綠色是 NMT 的結果,藍色是基於短語的翻譯系統的結果。
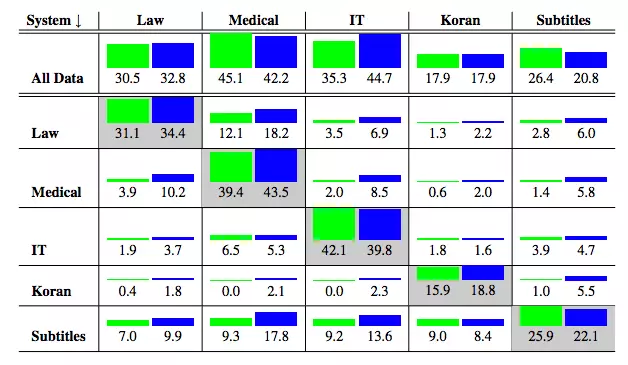
MT 系統在一個域上訓練並在另一個域 上進行測試。 藍色表示基於短語翻譯系統的表現,而綠色表示 NMT 系統的表現。
2. NMT 系統在小數據集上的表現很差。 雖然這算是機器學習的通病,但這個問題在 NMT 系統中體現尤其明顯。 相比基於短語的 MT 系統,雖然 NMT 系統隨著數據量的增加能進行更好地概括 ,但在小數據量情況下 NMT 系統的表現確實更糟糕。
引用作者的話來說,在資源較少的情況下,NMT 系統會產生與輸入無關的輸出,儘管這些輸出是流暢的。 這可能也是 Motherboard 那篇文章中探討 NMT 系統表現怪異的另一個原因。
3. Subword NMT 系統在罕見詞彙上的表現很糟糕。 雖然它的表現仍然要好過基於短語的翻譯系統,但對於罕見或未見過的詞語,NMT 系統表現不佳。 例如,那些系統只觀察到一次的單詞就會被 drop 掉。 像 byte-pair encoding 這樣的技術,對解決這個問題有所幫助,但我們有必要對此進行更詳細的研究。

我們可以看到圖中像土耳其語這樣的語言,遇到詞的變形形式是很常見的。
4. 長句。 以長句編碼並產生長句,這仍然是一個開放的、值得研究的話題。 在法律等領域,冗長複雜的句子是很常見的。 MT 系統的性能將隨句子長度而降級,而 NMT 系統亦是如此。 引入註意力機制可能會有所幫助,但問題還遠未解決。
5. 注意力機制不等於對齊。 這是一個非常微妙但又很重要的問題。 在傳統的 SMT 系統中,如基於短語的翻譯系統,語句對齊能夠提供有用的調試信息來檢查模型。 但即便論文中經常將軟注意力機制視為“軟對齊”,注意力機制並不是傳統意義上的對齊。 在 NMT 系統中,除了源域中的動詞外,目標中的動詞也可以作為主語和賓語。
6. 難以控制翻譯質量。 每個單詞都有多種翻譯,並且典型的 MT 系統對源句的翻譯好於 lattice of possible translations。 為了保持後者的大小合理,我們使用集束搜索。 通過改變波束的寬度,來找到低概率但正確的翻譯。 而對於 NMT 系統,調整集束尺寸似乎沒有任何不利影響。
當你擁有大量數據時,NMT 系統的翻譯性能依然還是難以被擊敗的,而且它們仍然在大量地被使用。 關於通常我們所說的神經網絡模型的黑盒性,也有待進一步說明,如今的 NMT 模型也都受此影響。
*文章為作者獨立觀點,不代表虎嗅網立場
本文由 AI科技大本營 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文請於文首標明作者姓名,保持文章完整性(包括虎嗅注及其餘作者身份信息),並請附上出處(虎嗅網)及本頁鏈接。 原文鏈接:https://www.huxiu.com/article/255190.html
未按照規範轉載者,虎嗅保留追究相應責任的權利
http://www.buzzfunnews.com/20180726207.html
心情煩悶需要新鮮事刺激一下嗎?請上:http://www.buzzfunnews.com
沒有留言:
張貼留言